Paralex: lexicons of morphological paradigms
![]()
Paralex is a standard for morphological lexicons which document inflectional paradigms.
It strives to provide data which is FAIR, so it can be used automatically, CARE, so it respects and empowers language communities, and DeAR (our own set of principles), so we can create a virtuous data ecosystem. It was inspired by the Cross-Linguistic Data Formats (CLDF) standard, and adheres to a similar philosophy. We aim to keep the two standards compatible in order to facilitate inter-operability.
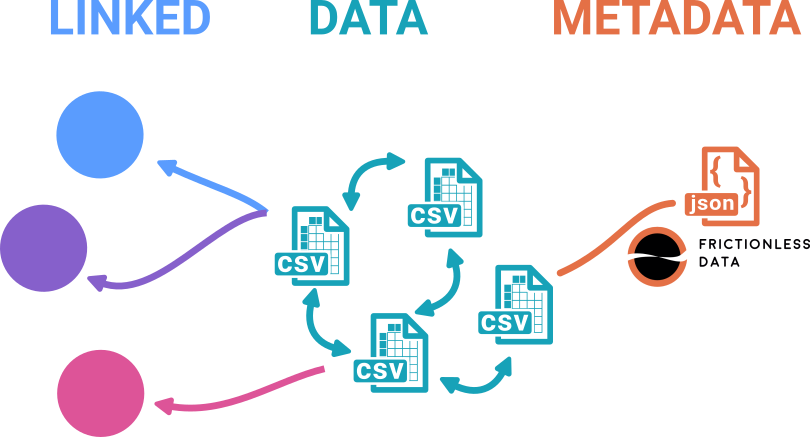
A paralex lexicon is a set of tables written as comma separated value (csv) files. It follows a relational model, tables are written in long form, metadata is written using the frictionless standard, and the tables respect pre-defined conventions. An ontology is also provided to allow converting paralex lexicons into RDF lemon/ontolex lexicons.
The standard is meant for sharing and interfacing, but not necessarily for data input. The expectation is for data creators to first input data through any convenient means, then convert the result into the standardized structure for publishing and sharing.
Available datasets
Contributors to the standard: Sacha Beniamine, Cormac Anderson, Mae Carroll, Borja Herce, Matías Guzmán Naranjo, Matteo Pellegrini, Erich Round, Helen Sims-Williams.